
Depuis quelques temps déjà on entend de plus en plus parler de serverless, d'Amazon Lambda, de FaaS (Function as a Service). Et en petit à petit on voit des comparatifs (en général sur les aspects financiers) pour mettre en relation ces nouvelles possibilités face aux infrastructures plus classiques genre machines virtuelles EC2 (pour rester chez Amazon). De ce que j'en ai lu ces comparatifs se trompent quasiment tous sur l'intérêt des Lambda et voici pourquoi.
Dernier en date que j'ai lu ici se propose de faire une analyse des coûts pour des scripts pythons ec2 vs lambda.
Il y a donc une série de benchmark (représentatifs de quoi, je ne sais pas) puis une analyse du coût en mode "x appels transformés en temps vs l'équivalent en ec2". Et c'est là toute l'erreur de la comparaison, elle ne représente absolument rien.
De la manière dont c'est comparé, il est évident que lambda n'a aucun intérêt. Mais que compare-t-on réellement au final ? On compare des instances EC2 et des lambda utilisées… comme des instances EC2. D'ailleurs pas besoin de faire beaucoup de calculs pour se rendre compte que plus on est flexible (reserved -> on demand -> lambda) plus ça coûte cher pour un même temps ou une même puissance.
Alors certes Lambda permet d'exécuter du code à la demande. Mais si vous vous arrêtez à ce point, vous n'avez absolument pas perçu tout l'intérêt des lambda ! Bien plus que de juste exécuter du code à la demande, les lambda permettent d'exécuter du code à la demande simultanément. Et oui, l'intérêt des lambda est dans la parallélisation.
Laissez-moi vous raconter un peu comment j'utilise les lambda et vous y verrez probablement un peu plus clair.
Sur une application que je développe en ce moment, j'ai 1000 lambda. 1000. Et parfois d'ailleurs j'ai en gros 2000 traitements à réaliser. Maintenant. Tout de suite. Comment ça se passe ? Les 1000 lambda vont bosser, puis dès qu'une va avoir terminé elle va dépiler les 1000 qui attendent. Et ensuite ? Ben rien, on va attendre le prochain set de traitement.
Maintenant, comment comparer ça à une infrastructure classique ? On n'est pas dans le cas où on peut juste prendre le temps de traitement d'un exemple et multiplier en disant "ha tiens, si j'en fait 1 000 000 ça va me coûter tant". Si je voudrais comparer et avoir la même chose sans les lambda il me faudrait genre 250 quad core de dispo. Et encore, je ne gère pas du tout l'infra dans lambda donc si une machine crash j'en ai une nouvelle, si je gère mon parc je rajoute un coût de maintenance non négligeable.
Mais admettons, j'ai mon parc de 250 quad core. J'en fait quoi ? Rien, en vrai il ne fait rien la (très) très grande partie de son temps. Et parfois il va bosser à fond jusqu'à saturer. Et ensuite il ne va absolument rien faire. Et voilà, la lambda va être là uniquement au moment où j'en ai besoin.
Alors si on parle tarif, en restant dans les grandes lignes, un tel cluster me coûterait plusieurs dizaines de milliers de dollars par mois. Et mes lambda me coûtent quelques dizaines de dollars par mois. Non non, je n'ai pas oublié de mot dans la phrase, et oui ça fait en général un facteur en centaines/millier entre les deux.
Evidemment, un jour, si tout marche très (très) bien, mes lambda bosseront tellement que ça arrivera au coût d'avoir des machines dispo tout le temps. Et oui à ce moment là il sera peut-être intéressant de passer sur une autre solution. Mais en attendant j'ai accès à une infrastructure massivement parallélisable et scalable. Pour presque rien.
D'ailleurs, c'est pas sans poser de problème. Il y a pas mal de difficultés à résoudre genre :
- comment faire pour qu'une lambda accède à S3, RDS et SQS sans problème de perf ?
- comment faire pour que les autres composants de mon infra (par exemple la base de données) soient capables de supporter le rythme des lambda ?
- comment gérer les problématiques de monitoring, log, etc ?
Comment faire pour qu'une lambda accède à S3, RDS et SQS sans problème de perf ?
Pour ce point, je pense qu'il faut surtout raisonner avec l'essence même des lambda : des fonctions. Il faut voir les lambda comme une grosse fonction. Et dans un programme comment fait-on quand on a une fonction qui grossit et qu'on n'arrive pas bien à gérer ? On la découpe en fonction. Et là c'est pareil. Ne pas hésiter à avoir une fonction (lambda) qui va appeler une fonction (lambda) et ainsi de suite. Et ça permet aussi de gérer encore plus finement les droits d'accès, la configuration réseau, etc.
Comment faire pour que les autres composants de mon infra (par exemple la base de données) soient capables de supporter le rythme des lambda ?
Problème classique, j'extrais un morceau de mon application qui fait appel à la base, je le pose dans une lambda. Je test, ça fonctionne parfaitement. Je test grandeur nature, j'ai 1000 accès concurrents dans ma base de données. Ma base de données n'aime pas du tout. Alors on peut imaginer dimensionner la base de données, mais c'est un peu la même histoire que pour EC2, on va dimensionner pour des pics et le reste du temps on va payer pour rien. Ou alors on utilise d'autres types de base, bases noSQL, S3 (et oui c'est une base au final), etc qui elles vont scaler correctement.
Comment gérer les problématiques de monitoring, log, etc ?
Alors là c'est un vrai problème. Amazon fourni des stats, avec le nombre d'erreurs, etc. Mais c'est pas simple. Et le log non plus (soit dit en passant que le log consomme du temps). Avec le temps je me dis qu'il faudrait plutôt un système (et architecturer) les lambda pour de la résilience à la panne. Une requête met trop de temps ? On tue la lambda et on la relance. C'est tout. C'est bourrin, mais les "problèmes" majoritaires qu'on rencontrent seraient en vrai traités de la sorte. Il y a un système de timeout dans les lambda, on peut aussi accéder à ces infos depuis la lambda. A tester.
A noter tout de même que depuis peu de temps la console d'AWS permet d'avoir un dashboard lié aux lambda. C'est sommaire mais ça présente des données aggrégées de l'usage des lambda. Voici un exemple, montrant le nombre d'invocation réalisés.
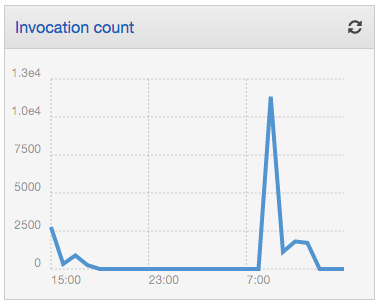
Cet exemple vous montre bien s'il en était besoin des possibilités d'usage. Très limité dans le temps, mais avec une puissance assez importante (le pic est à plus de 11000 invocations).
Aujourd'hui les lambda sont surtout la possibilité à quiconque d'avoir accès, ponctuellement ou non, à des puissances de calcul importante en simultané, parallélisable. Alors certes il y a des difficultés, quand on a l'habitude de gérer quelques threads, gérer 1000 exécutions concurrentes c'est pas toujours simple. Parfois ça leak tellement dans l'infrastructure qu'il faut envisager nos développement de manière totalement différente pour pouvoi dompter cette puissance et ne pas la freiner. Mais imaginez surtout que, pour un coût modique vous allez être capable d'offrir des fonctionnalités et une expérience utilisateur bien plus satisfaisante. Vos (dizaines de) minutes de traitements sur un serveur bien puissant se transformant en secondes en parallèle, c'est autant de temps d'attente que vous supprimez pour vos utilisateurs. Et on sait aujourd'hui que la réactivité est un élément clé d'une expérience utilisateur réussie.
Bref, utilisez des lambda !
Ha oui, et utilisez Terraform pour gérer vos lambda (et tout le reste), vous me remercierez plus tard.